Intel is firing back at AMD’s recent AI benchmarks that it shared during its Computex keynote that claimed AMD’s Zen 5-based EPYC Turin is 5.4 times faster than Intel’s Xeon chips in AI workloads. Intel penned a blog today highlighting the performance of its current-gen Xeon processors in its own benchmarks, claiming that its fifth-gen Xeon chips, which are currently shipping, are faster than AMD’s upcoming 3nm EPYC Turin processors that will arrive in the second half of 2024. Intel says AMD’s benchmarks are an ‘inaccurate representation’ of Xeon’s performance and shared its own benchmarks to dispute AMD’s claims.

As always, we should approach vendor-provided benchmark results with caution and pay close attention to the test configurations. We’ve included Intel’s test notes in the above album. These chips were all tested in dual-socket servers.
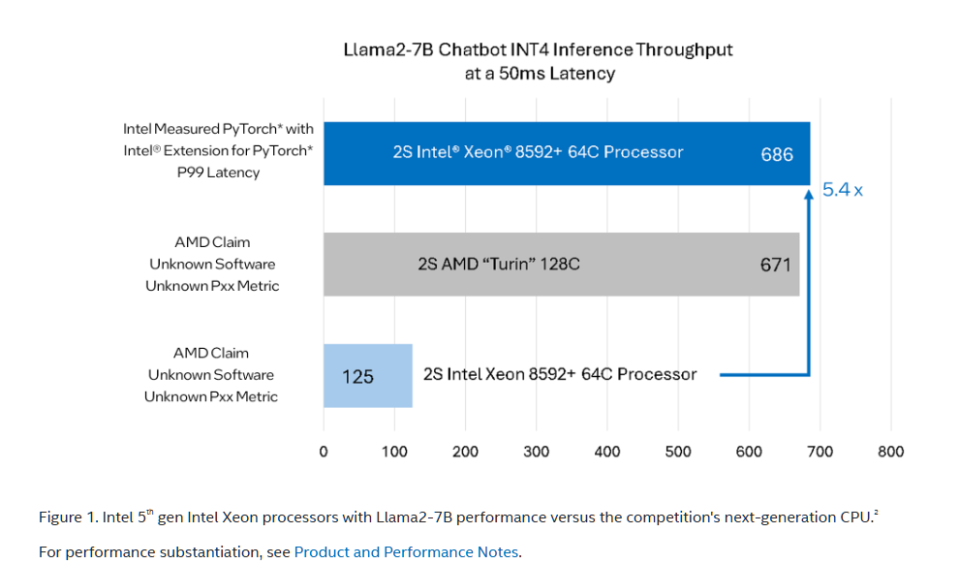
AMD’s benchmarks showed a range of advantages over Xeon, but the Llama2-7B chatbot results highlighted the most extreme win, showing a 5.4x advantage for the 128-core Turin (256 cores total) over Intel’s 64-core Emerald Rapids Xeon 8592+ (128 cores total).
Intel’s own internal results are in turn 5.4x faster than AMD’s benchmarks, thus giving the currently shipping 64-core Xeon an advantage over AMD’s future 128-core model — a quite impressive claim indeed, and quite the swing in performance.
Intel says AMD didn’t share the details of the software it used for its benchmarks or the SLAs required for the test, and we can’t find a listing of the batch sizes used (AMD test notes below). Regardless, Intel says AMD’s results don’t match its own internal benchmarking with widely available open-source software (Intel Extension for PyTorch). Intel assumed a “stringent” 50ms P99 latency constraint for its benchmark and used the same INT4 data type.
If this benchmark represents true performance, the likely disparity here is Intel’s support for AMX (Advanced Matrix Extensions) math extensions. These matrix math functions boost performance in AI workloads tremendously, and it isn’t clear if AMD employed AMX when it tested Intel’s chip. Notably, AMX supports BF16/INT8, so the software engine typically converts the INT4 weights into larger data types to drive through the AMX engine. AMD’s current-gen chips don’t support native matrix math operations, and it isn’t clear if Turin does either.
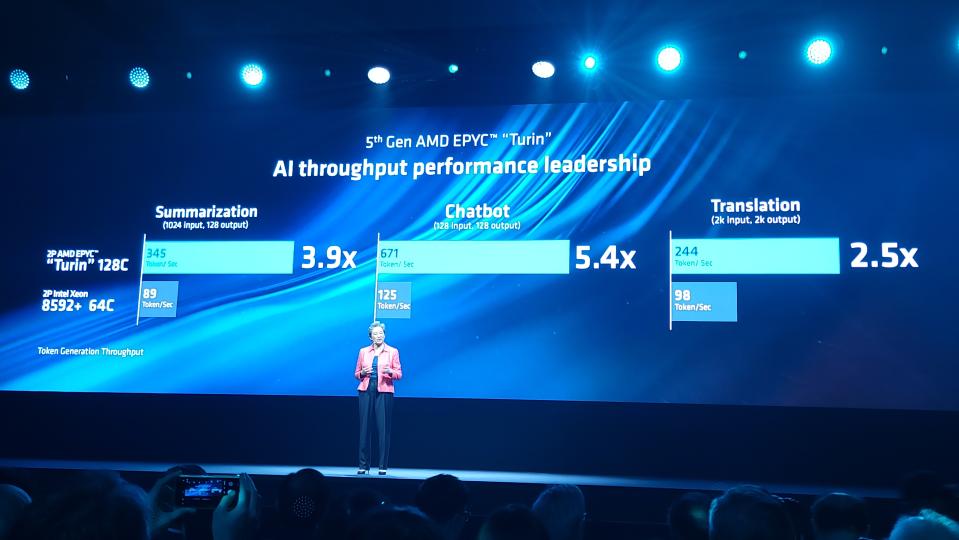


AMD’s Computex benchmarks also included Turin wins over fifth-gen Xeon in AI-driven summarization and translation workloads, claiming 3.9x and 2.5x advantages, respectively. Again, Intel begs to differ, with its own results showing 2.3x and 1.2x higher performance than AMD attained with the Xeon 8592+.
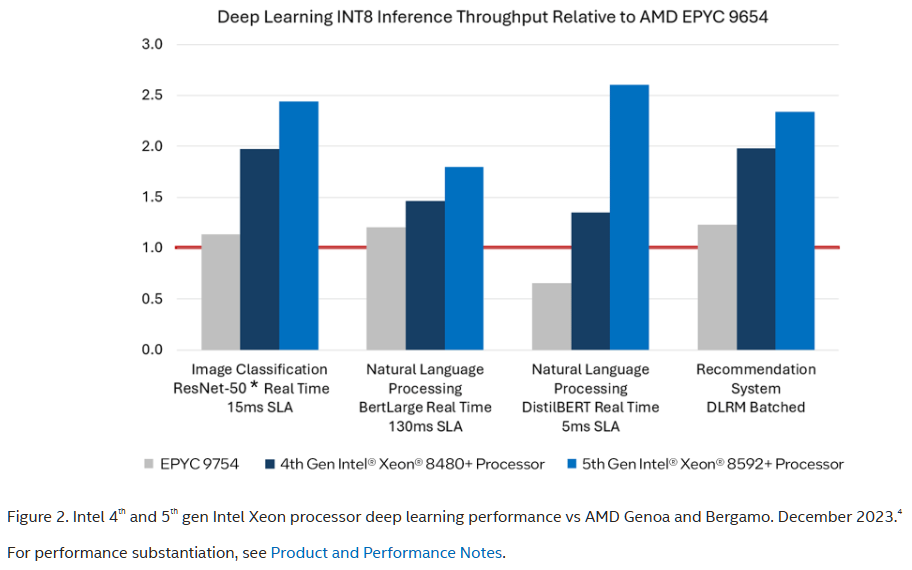
Intel doesn’t align its benchmark results against AMD’s Turin claims for this chart (we included AMD’s claims above). Instead, it chose to compare to AMD’s shipping 96-core EPYC 9754 processors and shows performance gains as a relative percentage against that chip. AMD’s test notes (last slide above) don’t indicate which models it used for its summarization and translation workloads, so it doesn’t seem possible to work out the relative performance to Turin in these workloads. However, it does seem that Turin would still come out on top in these benchmarks, but by a slimmer margin.
Notably, Intel claims that even its last-gen Xeons are faster than AMD’s current-gen EPYC Genoa and that its newer fifth-gen chips are up to 2.5x faster than Genoa.
Intel’s blog points out that its even newer Granite Rapids Xeon 6 chips, not benchmarked here, support up to 2.3x the memory bandwidth over its current-gen chips used here as a byproduct of moving from eight memory channels to 12, along with support for bandwidth-boosting MCR DIMMs. As such, it expects even higher performance in these workloads from its soon-to-launch chips. Intel’s newer chips also have up to 128 cores, which should help Intel’s performance relative to Turin — these comparisons are with 64-core models. Notably, Intel didn’t provide a counter to AMD’s claims that Turin is 3.1x faster in molecular dynamics workloads in NAMD.
Thoughts
The AI benchmark wars are heating up as Intel and AMD vie for a leadership position in AI workloads that run on the CPU. It’s harder than ever to take vendor-provided benchmarks at face value — not that we ever did anyway. That said, we do expect to see clearly defined benchmark configurations with vendor-provided benchmarks, and AMD’s Turin test notes don’t meet that bar. To be clear, Intel also doesn’t fully describe its comparative test platforms at times, so both vendors could improve here.
Notably, Intel does submit its CPU and Gaudi test results to the publicly available industry-accepted MLPerf database to allow for easily verifiable AI benchmark results, whereas AMD has yet to submit any benchmarks for comparison.
We expect the tit-for-tat benchmarking to only intensify as both companies launch their newest chips, but we’ll also put these systems to the test ourselves to suss out the differences. We currently have Intel’s Xeon 6 chips under the benchmarking microscope; stay tuned for that.
In the meantime, we’ve contacted AMD for comment on Intel’s counterclaims and will update you when we hear back. Optimizations for AI workloads are becoming a critical factor, so that it’s quite easy to see massive gains — or losses — in relative performance. Even on GPUs, we’ve seen performance improvements over time of 100% or more. Clearly, this won’t be the last we see of comparisons between tuned and untuned configurations.
Signup bonus from


